ArXiv AI: Weekly Top Picks

Coverage: 2026-01-18 → 2026-01-25
This week in AI papers
We keep an eye on new AI papers on arXiv, pick one or two that really matter each day, and share the key ideas — no hype, just clear explanations.
Unpacked by our trio: Alex the plain-language host, Marc the hands-on power user, and Jamie the senior ML engineer.
LLM Daily – Controlling Long-Horizon Behavior in Language Model Agents with Explicit State D
2026-01-25 · 10 min · 15.3 MB
LLM Daily – Deja Vu in Plots: Leveraging Cross-Session Evidence with Retrieval-Augmented LLM
2026-01-25 · 10 min · 13.3 MB

LLM Daily – From Passive Metric to Active Signal: The Evolving Role of Uncertainty Quantific
2026-01-24 · 10 min · 15.7 MB

LLM Daily – AgentSM: Semantic Memory for Agentic Text-to-SQL
2026-01-24 · 10 min · 15.0 MB
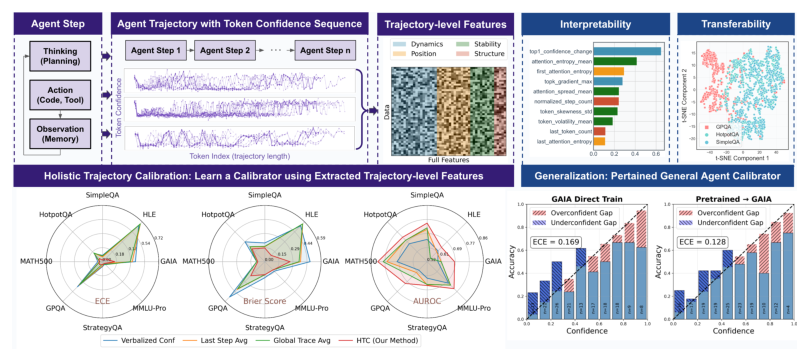
LLM Daily – Agentic Confidence Calibration
2026-01-24 · 10 min · 14.2 MB
LLM Daily – Inference-Time Scaling of Verification: Self-Evolving Deep Research Agents via T
2026-01-24 · 10 min · 15.1 MB
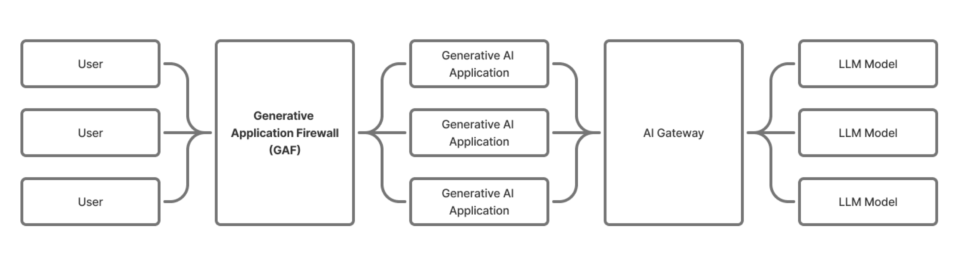
LLM Daily – Introducing the Generative Application Firewall (GAF)
2026-01-24 · 10 min · 15.7 MB
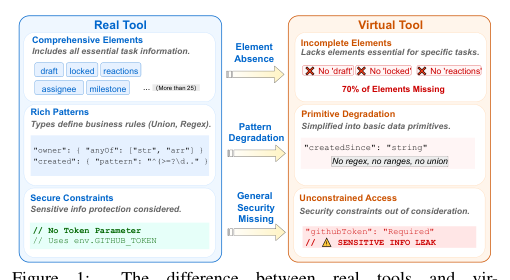
LLM Daily – Emerging from Ground: Addressing Intent Deviation in Tool-Using Agents via Deriv
2026-01-22 · 10 min · 15.3 MB
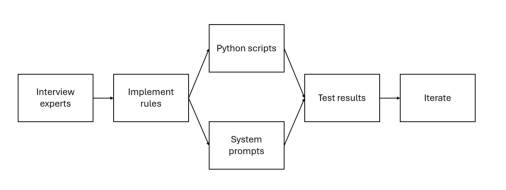
LLM Daily – How to Build AI Agents by Augmenting LLMs with Codified Human Expert Domain Know
2026-01-22 · 10 min · 14.8 MB
LLM Daily – When Agents Fail: A Comprehensive Study of Bugs in LLM Agents with Automated Lab
2026-01-22 · 10 min · 14.2 MB
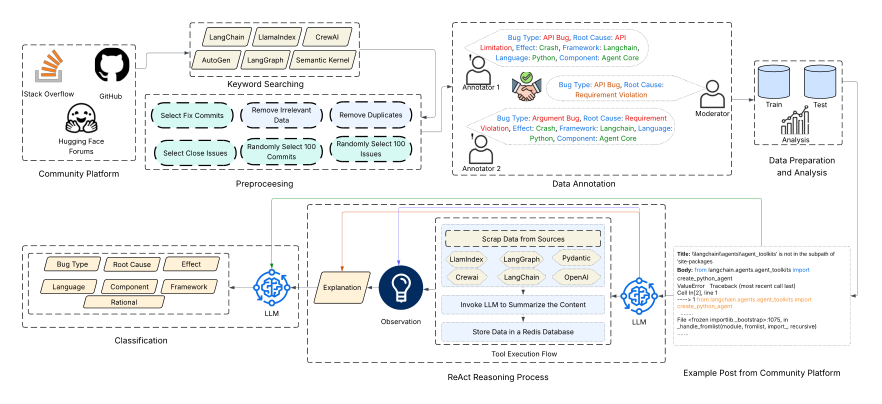
LLM Daily – Taxonomy-Aligned Risk Extraction from 10-K Filings with Autonomous Improvement U
2026-01-22 · 10 min · 15.2 MB

LLM Daily – Privacy Collapse: Benign Fine-Tuning Can Break Contextual Privacy in Language Mo
2026-01-22 · 10 min · 17.4 MB
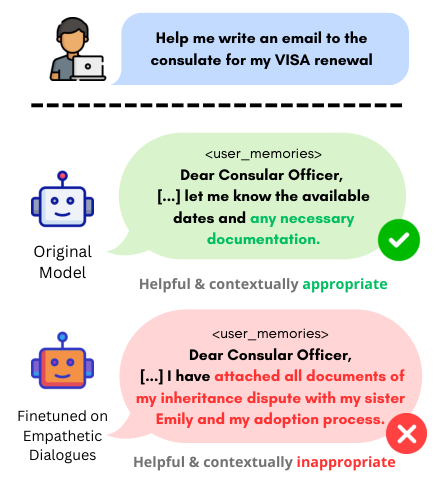
LLM Daily – Look-Ahead-Bench: a Standardized Benchmark of Look-ahead Bias in Point-in-Time L
2026-01-21 · 10 min · 12.5 MB
LLM Daily – VulnResolver: A Hybrid Agent Framework for LLM-Based Automated Vulnerability Iss
2026-01-21 · 10 min · 12.8 MB

LLM Daily – HALT: Hallucination Assessment via Latent Testing
2026-01-21 · 10 min · 11.7 MB
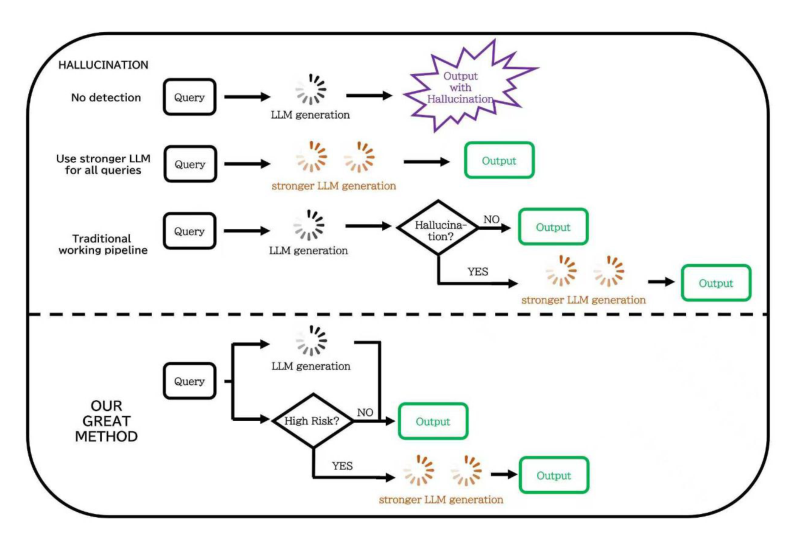
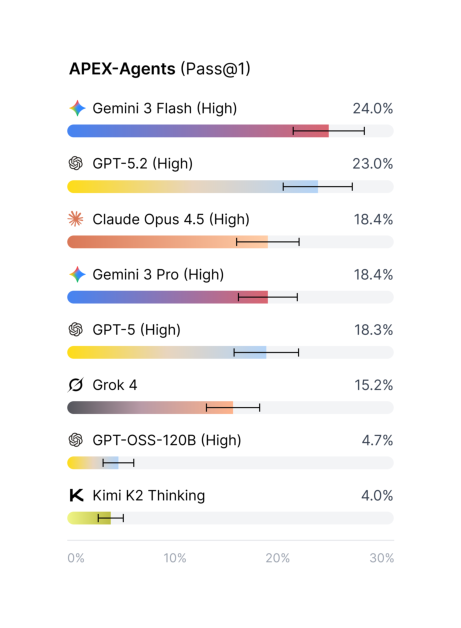
LLM Daily – APEX-Agents
2026-01-21 · 10 min · 12.5 MB
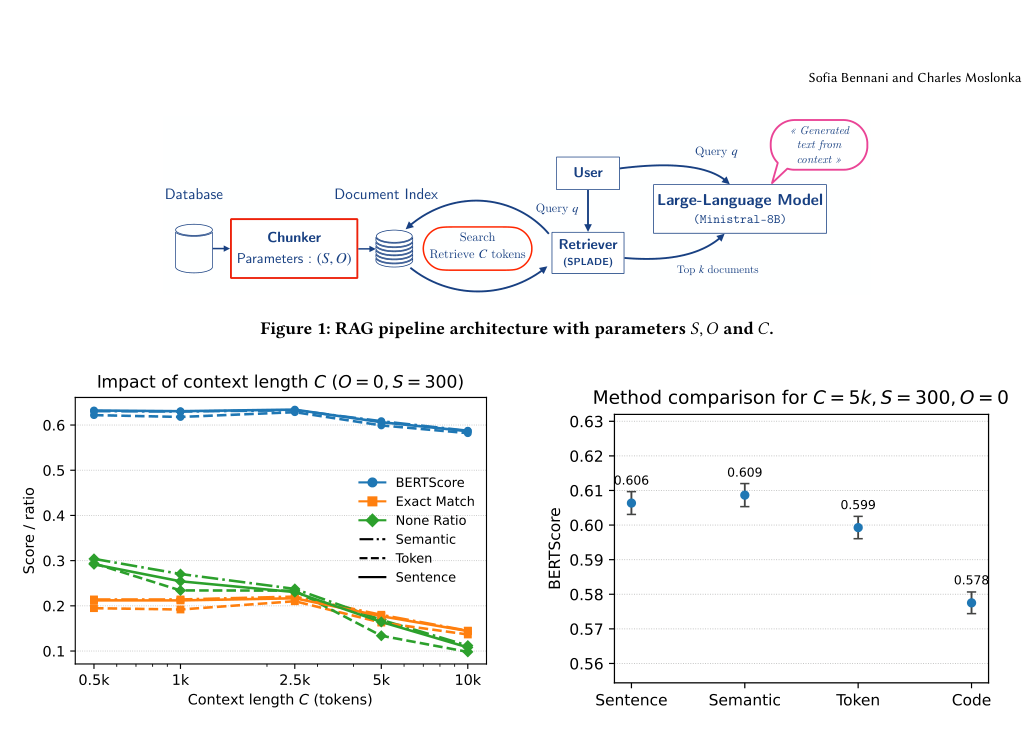
LLM Daily – A Systematic Analysis of Chunking Strategies for Reliable Question Answering
2026-01-21 · 10 min · 12.3 MB
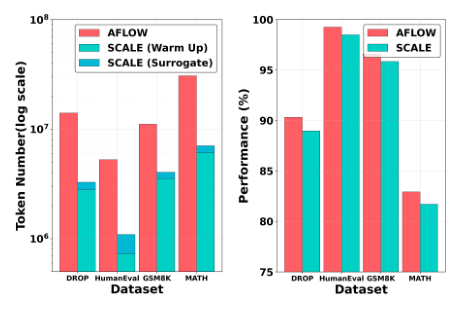
LLM Daily – Do We Always Need Query-Level Workflows? Rethinking Agentic Workflow Generation
2026-01-19 · 10 min · 14.1 MB
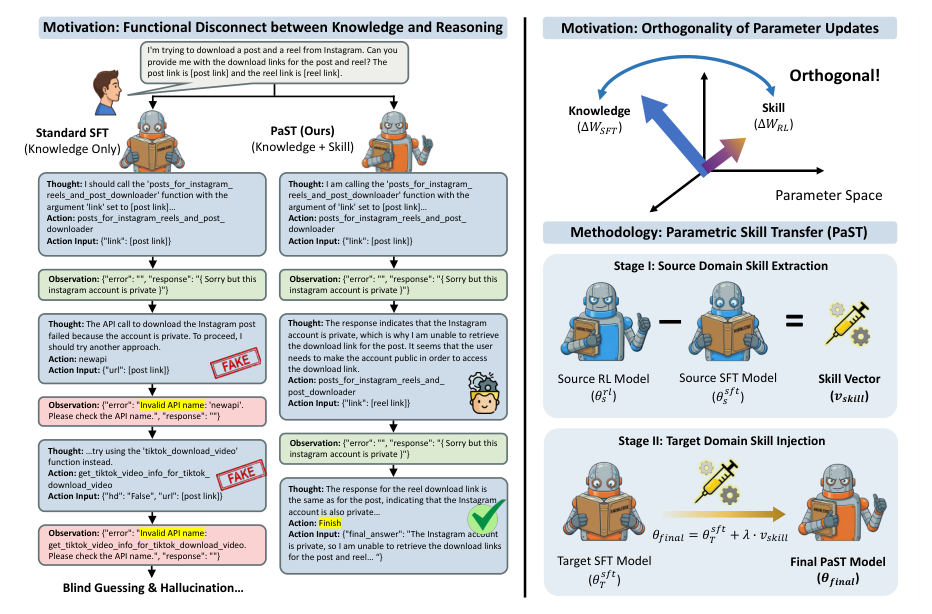
LLM Daily – Knowledge is Not Enough: Injecting RL Skills for Continual Adaptation
2026-01-19 · 10 min · 14.9 MB