Harry Potter and the magical embeddings

Have you ever wondered how machines understand human language, images, or even complex concepts? The answer often lies in the fascinating world of embeddings.
What are embeddings? Embeddings are essentially numerical representations of different types of data—think words, images, or sounds. They map data to vectors in multi-dimensional space, making it easier for algorithms to analyze and understand the underlying patterns.
Let's delve into the intricacies of this fascinating concept and examine how embeddings are transforming the way machines comprehend and engage with the world.
Scoring of Words and Sentences
Let's begin with a straightforward example where we compare individual words, then progress to a more complex example involving sentences to understand how these scores are calculated.
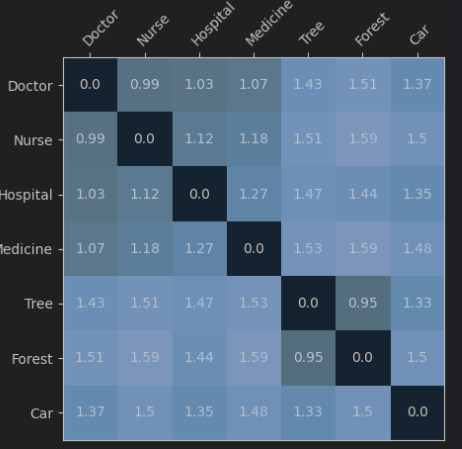
We can compare the embeddings of the following seven words: doctor, nurse, hospital, medicine, tree, forest, and car. Each word (listed by row) is compared to the others (listed by column). The closer two words are in meaning, the smaller their value will be. To achieve this, we'll utilize the text-embedding-3-large model from OpenAI, which is their most sophisticated embedding model.
The table below illustrates that the term "Nurse" is closely related to "Doctor" (0.99) and "Hospital" (1.12), but significantly distant from "Car" (1.5). Similarly, "Tree" is closely associated with "Forest" (0.95) yet far removed from "Medicine" (1.53). Lastly, it is evident that "Car" does not show a close association with any of the other terms provided..
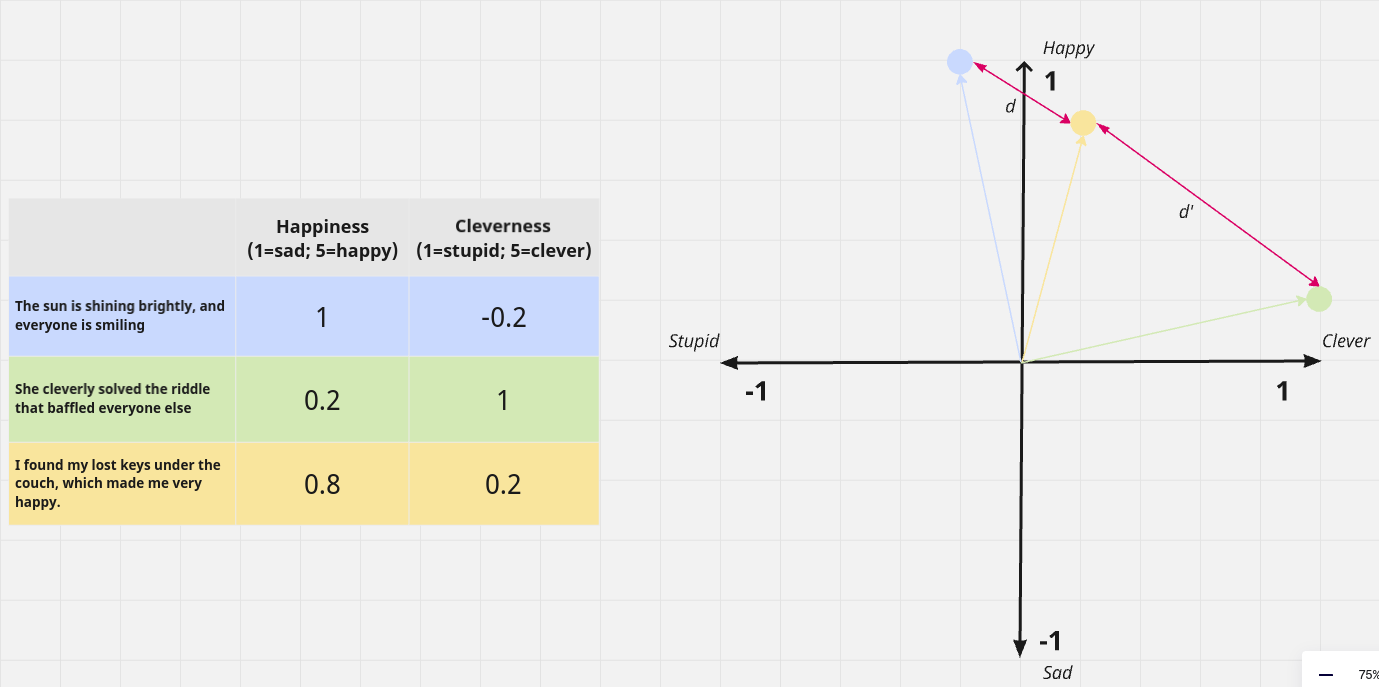
To understand the workings of this process, let's move on to our second example. We will examine three sentences, each of which will be scored based on two criteria: happiness and cleverness. Here are the three sentences:
- "The sun is shining brightly, and everyone is smiling."
- "She cleverly solved the riddle that baffled everyone else."
- "I found my lost keys under the couch, which made me very happy."
We can use a scale ranging from -1 to 1 to score these sentences, where -1 represents a low level and 1 represents a high level for both happiness and cleverness.
- "The sun is shining brightly, and everyone is smiling."
- Happiness: 1
- Cleverness: -0.2
- "She cleverly solved the riddle that baffled everyone else."
- Happiness: 0.2
- Cleverness: 1
- "I found my lost keys under the couch, which made me very happy."
- Happiness: 0.8
- Cleverness: 0.2
By evaluating sentences in this manner, we can represent them in a two-dimensional space with happiness and cleverness as the axes. Each sentence is represented by a point in this two-dimensional space, with each dimension capturing a specific aspect of the data. This is illustrated in the graph below, on the right of the figure.
Since embeddings are multi-dimensional vectors, they can be compared and ranked using metrics such as Euclidean distance. For example, in the graph below, each point represents a sentence embedding:
- The distance d between the first (blue) and second (green) sentences is shorter than the distance d' between the second (green) and the third (yellow) sentences.
- This suggests that the blue and yellow sentences are semantically closer to each other, in comparison to other pairs of green and yellow sentences, for instance.
Using this technique, it is easy to understand how sentences can be ranked based on their similarity. This is the fundamental principle behind semantic search and is heavily employed in RAG (Retrieval-Augmented Generation), which we will discuss on another occasion.
Put simply, embeddings convert text (whether it be words, sentences, or entire paragraphs) into vectors of real numbers. These vectors encapsulate the semantic meaning of the text, with each dimension in the vector representing different nuanced aspects of that meaning. To measure the similarity between embeddings, we can employ techniques such as cosine similarity or Euclidean distance.
Dimension of embeddings
Regardless of text length, embeddings yield a fixed-size vector. For example, OpenAI's text-embedding-ada-002 generates a 1536-dimensional vector and text-embedding-3-large has 3072 dimension. But what are the criteria used to classify and score the data? Let's focus on 20 commonly used factors :
- Semantic Similarity: How similar the meanings of words or phrases are, often used for tasks like synonym detection.
- Contextual Information: The context in which the words appear, heavily utilized in models like BERT.
- Part of Speech: The grammatical category of words (nouns, verbs, adjectives, etc.).
- Syntax Structure: The syntactical relationship between words in a sentence.
- Named Entities: Identification of proper nouns and specific entities like names of people, places, brands.
- Sentiment Polarity: The sentiment conveyed by the text, whether positive, negative, or neutral.
- Topic Modeling: The underlying subjects or themes within the text.
- Phrase Similarity: The closeness in meaning of larger text spans.
- Polysemy Detection: Differentiating between multiple meanings of the same word based on context.
- Discourse Relations: Connections between different parts of the text, such as cause and effect.
- Temporal Information: Time-related aspects mentioned in the text.
- Geographical Information: Place-related details contained in the text.
- Word Morphology: The structure and formation of words, including prefixes and suffixes.
- Coreference Resolution: Linking pronouns or entities to their respective nouns or subjects within a text.
- Register/Formality: The level of formality or informality in the text (e.g., formal vs. slang).
- Text Coherence: Logical flow and consistency throughout the text.
- Speaker Attribute: Information about the speaker such as gender, age, and style.
- Pragmatics: The implied meanings and inferred information not explicitly stated.
- Idiomatic Expressions: Recognition and understanding of idioms and colloquial phrases.
- Cultural References: Identifying references that are specific to certain cultures or groups.
As you can observe from the list, some criteria are intrinsic to the words themselves, while others depend on the context.
Intrinsic Criteria: These relate to the properties of the element itself.
- For a word: its meaning, part of speech, common usage, etc.
- Example: For words like "king" and "queen", intrinsic criteria could capture the notions of royalty and gender
Contextual Criteria: These depend on the surrounding text that contains the element.
- For a word within a sentence: its relationship to neighboring words.
- Example: The word "bank" in "river bank" vs "money bank". Here, "river" and "money" provide the context that influences the word's embedding.
The length of the text to be embedded
Because the vector size remains constant, the length of the text has a significant impact on the quality and information density of embeddings. Longer texts provide more context, but this context needs to be effectively condensed into the fixed-dimensional space. This means the embedding process must distill and represent the essential information from potentially lengthy inputs into the same-sized vector
When discussing techniques like Retrieval-Augmented Generation, we’ll see that the method of splitting text into chunks is pivotal and must be tailored to suit different scenarios. Proper chunking ensures the embeddings remain informative and contextually relevant, facilitating better retrieval and generation performance
Here is an example of a text and its corresponding embedding vector (partial), generated using text-embedding-ada-002
"Chapter 9: Approaches and Landings nIntroduction nThere is an old saying that while takeoff is optional, landing is mandatory. In consideration of that adage, this chapter focuses on the napproach to landing, factors that affect landings, types of landings, and aspects of faulty landings. A careful pilot knows that the safe outcome of a landing should never be in doubt. Pilots who respect their own limitations are able to approach each landing with confidence and achieve the satisfaction that comes from successful aircraft control. After any landing, a pilot performs a self-evaluation. If there is a question, a read of the relevant section in this chapter may help. When needed, additional flight instruction enhances safety. nThe manufacturer’s recommended procedures, including airplane configuration and airspeeds, and other information relevant to"
[0.006401168,-0.0028284618,0.0137635125,-0.03553683,-0.019090032,0.0163667,-0.016113056,-0.00024655176,-0.03059745,-0.028061012,0.0026549161,-0.0070820013,-0.032786798,0.0070219277,-0.006654812,-0.0038113315,0.017461373,-0.02282794,0.001138894,-0.018475948,-0.021386176,0.022641044,-0.015272026,-0.018142205,-0.009077777,0.01715433,0.018115506,-0.018062107,-0.015725914,-0.0056102,0.0071754493,0.012248325,-0.009217949,-0.010913357,-0.0048859804,-0.021719918,-0.004238521,-0.011106928,0.0034158474,-0.013276249,0.03874075,0.022334002,-0.014631242,-0.001049618,-0.018222304,-0.0042819073,0.013476495,-0.012275024,-0.028328005,0.038073268,0.017247777,0.010312622,-0.018609444,-0.03743248,0.005960629,0.017715016,0.0074424427,0.031718824,-0.0019490522,-0.005253096,-0.02979647,0.0036911846,-0.0086305635,0.024937188,-0.005450004,0.0036644852,-0.003304044,0.015245326,-0.012275024,-0.0050228145,
....
-0.0034024979,-0.0041050245,-0.027660523,0.00012723907,-0.023495425,0.04239856,-0.008370245,0.021145882,-0.004462128,-0.017274477,0.028354704,-0.013937058,0.036951896,-0.016473496,0.002993664,0.0073489947,0.0015151879,0.0037512581,-0.020958986,-0.022387402,-0.020465048,-0.011313847,-0.0040683127,0.010733137,-0.0007784528,0.056282222,0.037672777,-0.0070419526,0.0060474016,-0.012001356,0.021906814,-0.0060607516,-0.016353348,-0.014484395,-0.013116053,0.00387808,-0.013229526,0.01708758,-0.017261127,-0.00081474724,-0.024536699,-0.01467129,0.002357886,-0.010579616,-0.013035956,0.04085,-0.042745654,0.017207729,0.0030787683,-0.025644721,-0.002214377,0.033374183,0.0035743748,-0.037485883,-0.021412876,-0.009571715,0.02081214,-0.047498137,-0.0077828593,0.021039084,-0.01163424,-0.0034275285,-0.009878757,0.032946993,0.013229526,0.018195605,-0.016073005,-0.012528668,-0.029022189,-0.011387271,0.012281699,-0.0016420097,0.0042485334,-0.021025734]I hope you found this helpful. If you have any questions, please feel free to contact me.



