Making Every Word Count: The Bahdanau Attention

Last time, we followed Poirot and his little gray cells to gain an understanding of how RNNs work. Now, let’s further investigate this series on neural network architecture and delve into the Bahdanau attention mechanism, with the assistance of the great Sherlock Holmes and his friend, Dr. Watson.
Sherlock Holmes is well-known for his quasi-superhuman observational capacity to discern details and employ them to build credible hypotheses. He places significant weight on nuances while giving less importance to elements that might seem obvious to others, such as his friend Watson. He explains this in "The Adventure of the Blue Carbuncle," where he states: "You see, but you do not observe. The distinction is clear. A great mind is capable of dissecting the details that may appear insignificant to a lesser intellect."
Now, we can put on our deerstalker hats and delve into the Bahdanau attention mechanism to understand how it helps a network emulate Holmes's keen ability to focus on critical details.
The Encoder - Decoder architecture
When they introduced the attention mechanism in 2014, Bahdanau and colleagues were using a RNN‐based encoder‐decoder architecture like the one visible in the schema bellow to translate longer sentences effectively.
An encoder-decoder model consists of two networks: the encoder, which performs a sequence-to-vector transformation, and the decoder, which executes a vector-to-sequence transformation. Specifically, the encoder transforms a sequence (input string) into a vector (set of internal states), while the decoder converts this vector back into a sequence (output string). This architecture is particularly useful for tasks such as language translation.
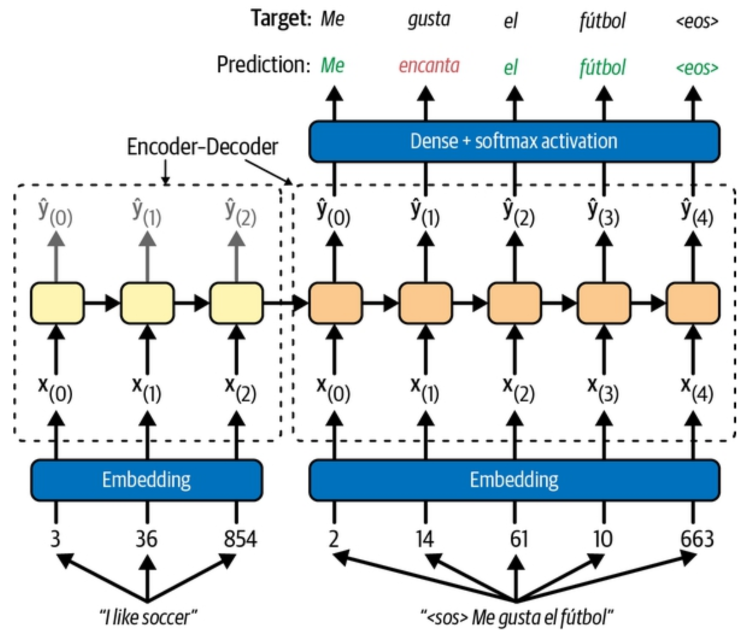
At every step in the encoding process, a RNN network (left of the schema) produces a state, denoted as ŷ(x). This internal state is then used as an input to the next step, along with the embedding of the second token, to generate the next state. Finally,
the final stateis passed to the decoder, which uses it alongside the first token of the target sequence to produce the expected token.
In the schema, "sos" stands for "start of sequence," a special character used for the first token. Thus, it is illustrated that the tokens are produced (at the top) one step before they are given as input (at the bottom). The dense layer (or head) is a simple layer that will convert the state to a token.
The architecture was not perfect. First, it suffered from the vanishing gradient problem. This means that for long sequences, information tended to be lost within the RNN, as new information in the gates often erased it. A second issue is that it was not very efficient; the entire sequence had to be processed in the encoder before the decoder could utilize the final state to produce tokens.
The Bahdanau attention
Bahdanau and colleagues decided to enhance this process. They intuitively felt that instead of solely using the last state produced (the arrow connecting the encoder and the decoder in the schema), they should consider all the states generated at each step by the encoder. The new architecture is visible in the following schema
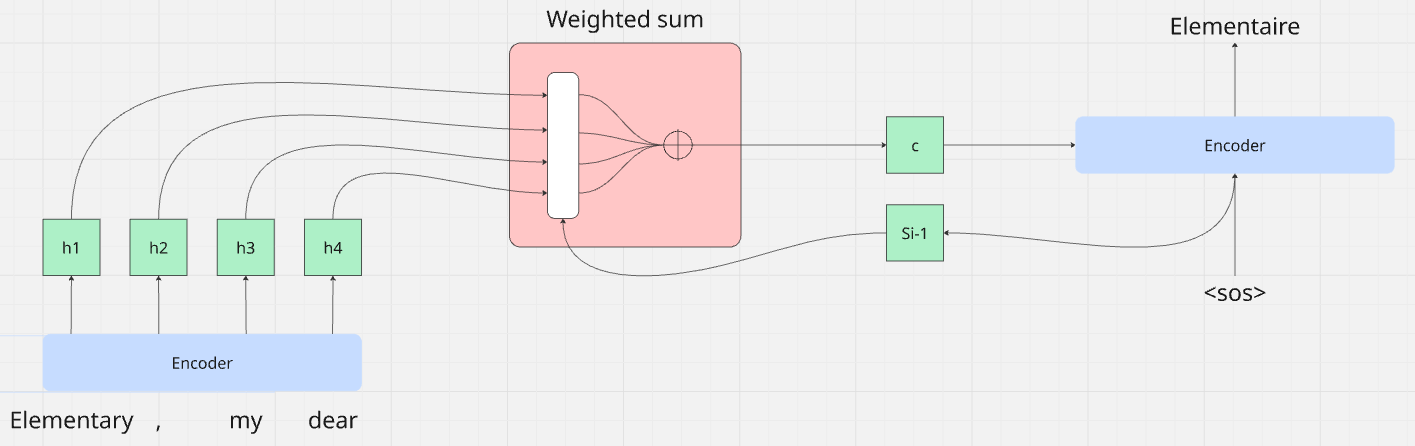
We learned in the last article that each encoder output was a representation of the semantic meaning of the current token given the presence of the other in the sequence. Bahdanau his colleagues envisioned that by utilizing a combination of the encoder states with the previous token generated by the decoder, they could get a better result
Measuring the alignment between words in different languages is hard. Even when a word has an unique translation in another language, both words may not have the exact same meaning depending on the context. Some words may be homonyms but with completely different meaning. Sometimes the word has the same position in the translated sentence, sometimes not. Therefore, having a precise understanding of the context is crucial for grasping the true meaning of the word
Take for example the word 'zone,' which is in the fifth position in the French sentence shown in the following schema. In English, it appears at the seventh position and is translated as 'area' rather than 'zone,' which also exists in English. The intensity of the alignment is represented by varying shades of white, so even if both words are different, the alignment is pretty high between them. You will notice that some words are associated with two or even three words in the translated sentence.

The objective of the alignment module introduced by Bahdanau et al. is to measure how each decoder state relates to each encoder state provided, producing an enhanced state with a higher level of integrated context. This enhanced contextualized state is then used to predict the next token.
The methodology
To measure this alignment, they first projected each generated encoder state and the previous decoder state into a neutral space before calculating the "alignment" between the two. Simplifying a bit, the output state is a weighted sum of all these alignments.
To understand what projection means—an important concept as it is heavily used in attention mechanisms—let's consider the French word "bureau." In English, depending on the context, "bureau" can be translated as either "desk" or "office." This means that in the embedding sequence of the French word, one dimension may be associated with "furniture," while another may relate to "place/location." However, in English word desk, the "place/location" dimension does not exist in the same way and the missing dimension may be used to represent a different concept
The alignment module learns during the training phase to assign greater importance to the "furniture" dimension and less to the "place/location" dimension. Similarly, the projection from the decoder state will help bridge the gap in the opposite direction, eliminating meanings or dimensions that do not exist in French.
This 'projection' into a neutral space is achieved by multiplying each encoder state by a learned matrix. Each element of this matrix is designed to harden or soften the corresponding dimensions of the embeddings, helping to align similar contextualized concepts in both languages.
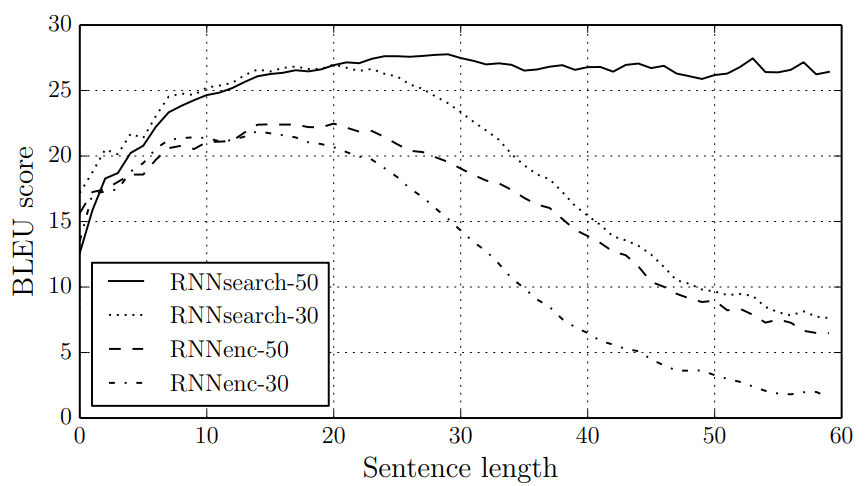
This is the core concept of attention. Now our network begins to 'see.' It can leverage the influence of all tokens to generate the next one and not only the last as in previous architecture. As the following table demonstrates, the vanishing gradient problem, which was clearly evident in sentences with 15 or 20 tokens, appears to stabilize using this method.
As we will see in the next article, this initial version of attention will be simplified and improved to lead to the mechanism used in current LLMs



